Using fMRI Data to Predict Autism Diagnoses with Various Machine Learning Models and Cross-Validation Methods
By Emily Chen, Andréanne Proulx, & Mikkel Schöttner
Published on June 11, 2020
| Last updated on
June 12, 2020
Project Definition
Personal Backgrounds
Emily (personal repository)
Hello! I am an (incoming) fourth year undergraduate student at McGill University studying computer science and urban health geography with a minor in cognitive science. I am a research assistant with Isabelle Arseneau-Bruneau in the Zatorre Lab and have been learning a lot about neuroscience research while (hopefully) lending some of my technical skills to Isabelle's PhD work exploring the effect of musical training on FFR.
When joining the BrainHack School, I was looking forward in particular to working on a project at the intersection of neuroscience and CS because my previous classes rarely focused on the application of the abstract concepts we learned. Upon completion of the BrainHack School, I had the opportunity to learn from and collaborate with talented neuroscience researchers and participants, write a machine learning script using python and neuroscience data, and gain hands-on practice in reproducibility efforts and good project management.
You can find me on GitHub at emilyemchen and on Twitter at @emilyemchen.
Andréanne (personal repository)
Hi! I am an incoming master's student in Psychology at the University of Montreal. My background is in cognitive neuroscience and my career objective is to work on research projects aiming to discover new ways of characterizing the brain in its pathological states. At the moment, I am working with Sébastien Jacquemont and Pierre Bellec, and the focus of our research is on investigating the effect of genetic mutations on functional and structural brain phenotypes. More precisely, I have been working with resting-state functional connectivity measures in carrier populations with developmental disorders.
By joining the Brainhack School, I hoped to strengthen my computational skills and my knowledge in the applications of machine learning to the field of neuroimaging. Not only did I get to work on a machine learning problem specific to my field, but I also got to learn about useful tools such as GitHub. More importantly, I also met a community of brilliant/aware researchers and got to collaborate with other students, even across the world!
Mikkel (personal repository)
Hey! I am a master's student in Cognitive Neuroscience at the University of Marburg. My background is in psychology. I am especially interested in the social brain and how humans infer thoughts and emotions from the actions of others. Right now, I am doing my Masters thesis on how the capacities of Theory of Mind and empathy interact in the brain using fMRI. I am also very much interested in research methods and how we can use statistics and data science techniques on neuroimaging data.
When getting into Brainhack School, I hoped to get a better understanding of machine learning, and how it is useful for analyzing fMRI data. I learned a lot about collaborative project organization, how to make pretty interactive plots and how to write better Python scripts. Brainhack School was really an awesome experience getting to know a lot of talented and motivated people and being able to collaborate with them across the Atlantic!
You can find me on GitHub at mschoettner and on Twitter @mikkelschoett.
Tools
We expected to use the following tools, technologies, and libraries for this project:
- Git
- GitHub
- Visual Studio Code
- Docker
- Jupyter Notebook
- HPC/Compute Canada
- Python libraries:
numpy,pandas,matplotlib,scikit-learn,nilearn,seaborn,pyplot,pyplot venv
Data
The goal of this project was to compare different machine learning models and cross-validation methods and see how well each is able to predict autism from resting state fMRI data. We used the preprocessed open source ABIDE database, which contains structural, functional, and phenotypic data of 539 individuals with autism and 573 typical controls from 20 different research sites.
Deliverables
By the end of The BrainHack School, we aimed to have the following:
README.mdfilerequirements.txtfile that outlines the packages needed to run the script- Jupyter notebooks with code and explanations
- GitHub repository documenting project workflow
- Presentation showing project results
Project Results
Project Background
Several studies have found an altered connectivity profile in the default mode network of subjects with Autism Spectrum Disorder, or ASD (Anderson, 2014). Based on these findings, resting state fMRI data have been used to predict autism by training a classifier on the multi-site ABIDE data set (Nielsen et al., 2013). This project's scientific aim is to replicate these findings and extends the literature by comparing the effects of differing cross-validation methods on various classification algorithms.
Becoming a Team
The three of us joined forces when we realized that we shared many similar learning goals and interests. With such similar project ideas, we figured we would accomplish more working together by each taking on a different cross-validation methods to train various machine learning models.
Team Project Management
We all shared a common interest in making our project as reproducible as possible. This goal involved creating a transparent, collaborative workflow that could be tracked at any time by anyone. To achieve this objective, we utilized the many features that GitHub has to offer, all of which you can see in action at our shared repository here.
- Branches: used to work simultaneously on our own parts and then push changes to the master branch
- Pull requests: created when making changes to the master branch
- Issues: used to communicate with each other and keep track of tasks
- Tags: used to keep issues organized
- Milestones: used to keep our main goals in mind (Week 4 presentation and final deliverable)
- Projects: used to track various aspects of our work
Standardized Data Preparation and Jupyter Notebooks
The data are processed in a standardized way using a Python script that prepares the data for the machine learning classifiers. Several Jupyter notebooks then implement different models and cross-validation techniques which are described in detail below.

Tools, Technologies, and Libraries Learned
Many of these contribute to open science practices!
- Jupyter Notebook: Write code in a virtual environment
- Visual Studio Code: Edit files such as
README.md - Python libraries:
numpy,pandas,nilearn,matplotlib,plotly,seaborn,plotly,sklearn(dimensionality reduction, test-train split, gridsearch, cross-validation methods, evaluate performance) - Git: Track file changes
- GitHub: Organize team workflow and project
- Machine learning: Apply ML concepts and tools to the neuroimaging field
venv: Makerequirement.txtfile for a reproducible virtual environment
Deliverables
Deliverable 1: Jupyter notebooks (x3)
Leave-site-out cross-validation
leave-site-out-cv_classifier.ipynb
This notebook contains code to run a linear support vector classification to predict autism from resting state data. It uses leave-group-out cross-validation using site as the group variable. The results give a good estimate of how stable the model is. While for most of the sites the prediction works above chance level, for some, autism is predicted only at or even below chance level.
K-fold and leave-one-out cross-validation
kfold-leave-one-out-cv_classifier.ipynb
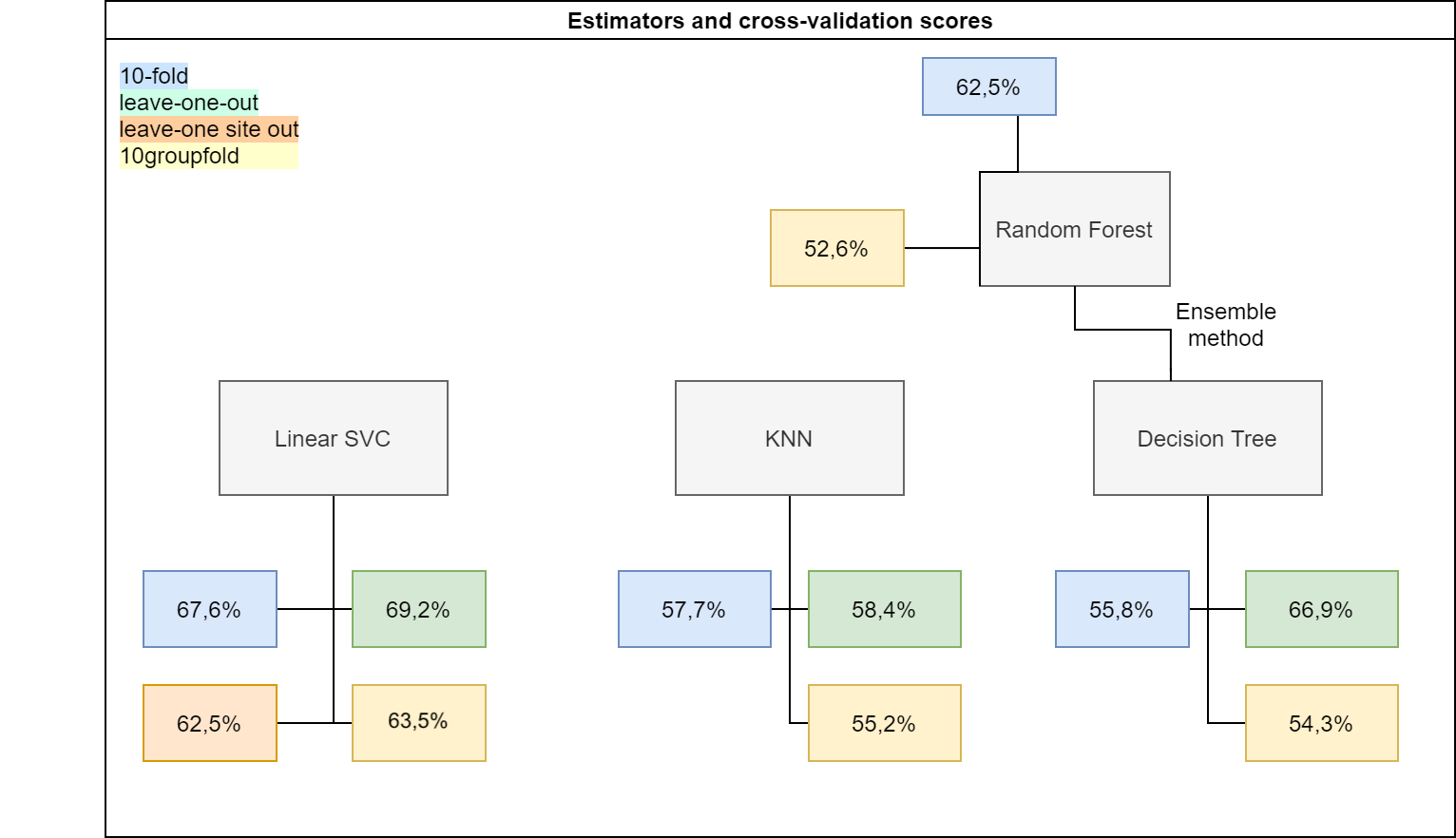
This notebook contains the code to run linear support vector classification, k-nearest neighbors, decision tree, and random forest algorithms on the ABIDE dataset. The models are trained and evaluated using k-fold and leave-one out cross-validation methods. We obtain accuracy scores that represent how skilled the model is at predicting the labels of unseen data. Leave-one out cross validation gives more accurate predictions than kfold cross validation. The accuracy values range from 55.8% to 69.2%.
Group k-folds cross-validation
group-kfolds-cv_classifier.ipynb
This notebook implements a 10-fold iterator variant to split the data into non-overlapping groups. It then runs four classification algorithms on the data: linear support vector machines (LinearSVC), k-nearest neighbors (KNeighborsClassifier), decision tree (DecisionTreeClassifier), and random forest (RandomForestClassifier). The most accurate classifier, LinearSVC, has an average accuracy score for all models of 63.5%, while the least accurate classifier, RandomForestClassifier, has an average accuracy score for all models of 52.6%. This latter percentage is not far off from the average accuracy scores of the other two classifiers. These scores are not particularly impressive, and one reason could be the data that this model is being trained on. Each site had differing processes, methods, and amounts of data they collected, so the lack of similarity could suggest less widespread generalizability. Future work into optimizing the parameters would be the logical next step.
Table 1: Group 10-fold cross validation average accuracy scores (percentages) per classifier algorithm
| Algorithm | Average Score | Maximum Score | Minimum Score |
|---|---|---|---|
LinearSVC | 63.5% | 72.0% | 52.3% |
KNeighborsClassifier | 55.2% | 66.7% | 48.7% |
DecisionTreeClassifier | 54.3% | 61.6% | 44.9% |
RandomForestClassifier | 52.6% | 60.5% | 39.7% |
What were the overall results?
Deliverable 2: prepare_data.py script
This script
- downloads the data
- extracts the time series of 64 regions of interest defined by the BASC brain atlas
- computes the correlations between time series for each participant
- uses a principal component analysis for dimensionality reduction
To fetch and prepare the data set you can call the prepare_data.py script like this:
./prepare_data.py data_dir output_dir
or alternatively:
python prepare_data.py data_dir output_dir
where
data_diris the directory where you want to save the data or have it already saved andoutput_diris the directory where you want to store the outputs the script generates.
The notebooks also call the prepare_data function from the preparation script.
Deliverable 3: requirements.txt file
This file increases reproducibility by helping to ensure that the scripts run correctly on any machine. To make sure that all scripts work correctly, you can create a virtual environment using pythons built-in library venv. To do this, follow these steps:
- Clone repo and navigate to folder in a shell
- Create a virtual environment in a folder of your choice:
python -m venv /path/to/folder - Activate it (bash command, see here how to activate in different shells):
source /path/to/folder/bin/activate - Install all necessary requirements from requirements file:
pip install -r requirements.txt - Create kernel for jupyter notebooks:
ipython kernel install --user --name=abide-ml - Open a jupyter notebook:
jupyter-notebook, then click the notebook you want to run - Select different kernel by clicking Kernel -> Change Kernel -> abide-ml
- Run the code!
Deliverable 4: Data visualizations (Week 3)
Click here for the website.
Click here for the website.
Click here for the website.
Click here for the website.
Click here for the website.
Click here for the website.
Click here for the website.
Deliverable 5: Presentation (Week 4)
The presentation slides can be viewed here on Canva, which is the platform we used to create the slides. A video of our presentation can be viewed on this project page. We presented our work to The BrainHack School on June 5, 2020 using the RISE integration in a Jupyter notebook, which can be found here.
Conclusion and Acknowledgement
First and foremost, we would like to thank our Weeks 3 and 4 peer clinic mentor and co-organizer of the Brainhack School, Pierre Bellec. A special thank you as well to our Week 2 mentors Désirée Lussier-Lévesque, Alexa Pichet-Binette, and Sebastian Urchs.
Thank you also to The BrainHack School leaders and co-organizers Jean-Baptiste Poline, Tristan Glatard, and Benjamin de Leener, as well as the instructors and mentors Karim Jerbi, Elizabeth DuPre, Ross Markello, Peer Herholz, Samuel Guay, Valerie Hayot-Sasson, Greg Kiar, Jake Vogel, and Agâh Karakuzu.
References
Choosing appropriate estimators with
scikit-learnhttps://scikit-learn.org/stable/tutorial/machine_learning_map/Benchmarking functional connectome-based predictive models for resting-state fMRI (for classification estimator inspiration) https://hal.inria.fr/hal-01824205
Getting the data using
nilearn.datasets.fetchhttps://nilearn.github.io/modules/generated/nilearn.datasets.fetch_abide_pcp.htmlPython Data Science Handbook GitHub and website https://github.com/jakevdp/PythonDataScienceHandbook
BrainHack School course materials and lectures https://github.com/neurodatascience/course-materials-2020
Scientific articles:
Anderson, J. S., Patel, V. B., Preedy, V. R., & Martin, C. R. (2014). Cortical underconnectivity hypothesis in autism: evidence from functional connectivity MRI. Comprehensive Guide to Autism, 1457, 1471.
Nielsen, J. A., Zielinski, B. A., Fletcher, P. T., Alexander, A. L., Lange, N., Bigler, E. D., … & Anderson, J. S. (2013). Multisite functional connectivity MRI classification of autism: ABIDE results. Frontiers in Human Neuroscience, 7, 599.